Visualizing Data: Challenges to Presentation of Quality Graphics—and Solutions
Naomi Robbins, a consultant and seminar leader who specializes in the graphical display of data, offers training on the effective presentation of data. She also reviews documents and presentations for clients. She is the author of Creating More Effective Graphs.
Three common challenges statisticians and others face when preparing data for presentation include poor options and defaults in many software packages used for creating graphs, managers and colleagues who are socialized to expect figures that attract attention, and poor instructions from conference organizers. This article addresses each of these challenges and offers some tips for dealing with them.
Poor Options and Defaults in Many Software Packages
Many software programs for drawing charts and graphs offer defaults and options that are full of fancy embellishments that detract from the clear and accurate communication of data. Some software vendors think graphs that wow the audience with the complexity of their artwork will produce more sales. Therefore, they include unnecessary dimensions, use confusing ribbons in place of lines, and offer graph forms that do not communicate well. Unfortunately, these frills and decorations may distort the data, make it more difficult to understand, and may lead to poor decisions being made based on the data.
Figure 1 shows the results of an Internet/mail survey of ASA members with six to 15 years of membership. The figure appears in the October 2005 issue of Amstat News. Members were asked if they agreed that their primary position was professionally challenging; they also were asked about the importance of increasing professional recognition. In addition, a number of demographic variables were included.
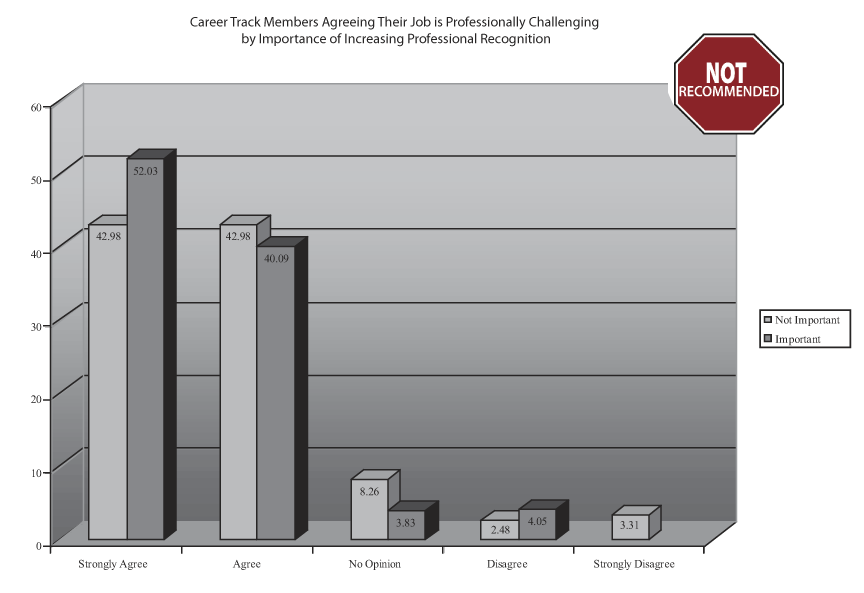
A major problem with pseudo-three-dimensional bar charts like this one is that almost no one reads them correctly. Note that the bar for “Agree/Important” is labeled 40.09; however, all points on the top of the bar lie below the grid line labeled 40. This happens because the bar does not touch the back wall.
I assume it was designed so a plane tangential to the top of the bar would look as if it were the correct height. It doesn’t work for me. This figure looks as if it was drawn using a version of Microsoft Excel prior to 2007 with the gap depth (i.e., the distance from the back of the bar to the back wall) set as the default. Note that gap depth is an option that can be changed in Excel. It confuses the audience when the labels do not match the visual representation.
The pseudo three-dimensional problem is easily solved by using a two-dimensional bar chart. In Excel, that means sticking with “2-D Column” or “2-D Bar” charts and never using what I call pseudo-three-dimensional charts: the “3-D Column,” “3-D Bar,” “Cylinder,” “Cone,” and “Pyramid” options. These are “pseudo” three-dimensional since they only display two dimensions, despite their 3D appearance. Data that are truly three-dimensional with three variables cannot be displayed with these charts. I often recommend Trellis displays, described in Creating More Effective Graphs, for plotting three variables.
There are numerous other problems with this figure. The small font size of the title, labels, and legend make them difficult to read. The grid lines are too prominent, distracting attention from the more important elements of the graph. The variably shaded gray background also takes attention away from the data. Some readers have difficulty interpreting the title when the graph is separated from the article in which it was originally published, since the full text of the article clarifies the title.
The diverging stacked bar chart of Figure 2 shows a much improved way of conveying all the information available in Figure 1, with the addition of a breakdown by employment sector, race, education, and gender. Yet, the figure takes about the same space as Figure 1.
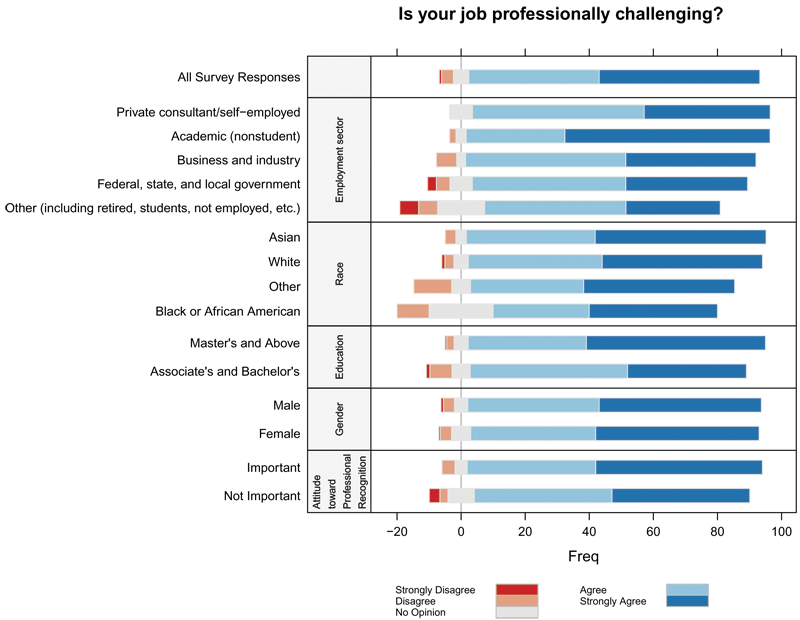
While standard stacked bar charts are difficult to read, centering the bars around zero (“No Opinion” in this case) makes it easy to check whether the majority in any subgroup find their job professionally challenging or not. The length of the bar to the right of zero shows the percent who agree that their positions are professionally challenging, while the length to the left of zero shows those who disagree. People with no opinion are split down the middle. The shading shows whether the agreement was strong.
In a glance, we can see which groups have the strongest agreement/disagreement. This is more difficult to notice from a table or separate bar graphs for each category, as in Figure 1. Figure 2, programmed by Richard Heiberger, uses a diverging stacked bar chart created with a forthcoming R function to be included in the HH package. Adding unnecessary dimensions is just one example of a poor option that occurs in many software programs. Other examples appear in Creating More Effective Graphs.
Managers and Colleagues Who Expect Figures That Attract Attention
Statisticians who are well versed in the principles of effective graphs often ask me how to convince their managers or colleagues that the figures requested are misleading or inappropriate. They say their bosses want figures with a “wow” factor. The first challenge and this one together form a vicious cycle: Managers like the decorated graphs that they see software vendors providing, and software vendors believe the managers prefer and demand them.
Almost no one would write a business report in a font that attracts attention, such as Algerian. Business writers reserve display fonts for single words or phrases in advertisements or for invitations to a child’s birthday party. There are a number of analogies about using display fonts and graphs that attract attention for the wrong reasons: They both emphasize the design, rather than the message the words or graphs are meant to communicate. They both show off the designer’s skills with technology. There may have been a day when people were impressed that you could produce these fancy graphs, but today it is no more impressive than knowing how to change fonts. I often find that making analogies with words helps others see the parallels and encourages them to show the same respect for numbers.
Another effective technique I use to convince others that their favorite graphs do not communicate well is to ask questions about the data that are difficult to answer from their preferred graph. As an exercise at meetings or seminars, participants answer questions about fancy graphs they did not draw. The people who proposed the graphs can readily see that colleagues misinterpret the data. For example, you could show Figure 1 without the data labels and ask how high the “Agree/Important” bar is. When most of the others in the room underestimate the value, the person who designed or requested it will likely realize its limitations.
A number of years ago, there was a discussion on S-news, a support group for the S-Plus software, about the use of pie charts. I still remember a message from Eric Gibson, who said that when he was asked to draw a graph he thought did not communicate well, he did not lecture the requester or play better than thou. He prepared what he was asked to do, but also what he thought should be done. Then, he delivered them, saying, “I always like to give my clients a choice.” Many times, the client would see the superiority of his method and use his figure.
A number of statisticians have told me they like to give a book emphasizing principles of effective graphs to their management or clients who request graphs they dislike. Another option is to arrange for a seminar or short course for the department or organization about communicating data clearly. Offering training courses is often the solution when it is management that appreciates communicating data clearly and staff who include unnecessary decorations in their charts.
Poor Instructions from Conference Organizers
A number of conferences advise their speakers to use yellow text on a dark blue background. They claim these are the easiest to read. I’ve seen articles about effective presentations that recommend light on dark and others that recommend dark on light. There is a problem when light on dark is used and handouts are made from the slide decks, since the colors are inverted for the handouts so the text shows up. The problem is that the original graphs usually have a light background with dark data markers and text. Then, when the colors are inverted, the graphs are illegible.
Also, the handouts are often black and white, even if the original slides were in full color. Any colors used to distinguish points or lines are lost. Handouts are often referred to years after a presentation, so intelligible handouts are essential. I have seen many prominent statisticians with useless handouts since they followed the directions of the conference organizers. The solution: Just say no. I have refused to use yellow on navy, but explained my reasons. The conference organizers replied that they wished other speakers gave as much thought to their handouts.
Summary
Even statisticians well acquainted with the principles of effective graphs face challenges when trying to visualize data. These challenges may be caused by the software the graph designer is required to use, the instructions given by management, or the instructions given by conference organizers. Solutions include recognizing these problems so you choose software options and software carefully, selecting a method for communicating with management that you are comfortable with and is appropriate for the situation, and considering the consequences of following instructions when preparing slides for presentations and speaking up if necessary.








 (2 votes, average: 5.00 out of 5)
(2 votes, average: 5.00 out of 5)
Naomi, an excellent overview and advice. As a long-time statistician, I was not taught in graduate school about effective communication of results with graphs and tables. This has been a great weakness working in the corporate world, but I have addressed it on my own with multiple books (Few, Tufte), practice and reviewing many good examples- like yours above.
This is a real impediment facing many statisticians, since the ultimate purpose of statistics is to inform and explain. When dealing with the public and decision-makers, the field has often failed by placing a wall of details between their hard work and their intended audience.
Statisticians don’t need to become experts at graph selection and design, but they should at least become proficient. They will find much greater success in obtaining grants and succeeding in the corporate world.
Here is a free resource (on the iPhone and Android) that we created for graph selection, creation and refinement, The Rapid Dashboards Reference“.
Keep up the good work!
Stephen McDaniel
Freakalytics, LLC
Dear Dr. Robbins,
Interesting article. I haven’t read your book, but will try. I’ve written a letter/editorial which is going to be published in the Jr. of Computational & Graphical Stats in the Sept.,11 issue, which is relevant, and where I make the distinction between graphs for presenting data to audiences, which seems to be your primary concern, and graphical data analysis. An excerpt is below:
“……I’ve always looked at graphs as serving two primary functions in statistics: one is presenting data to an audience (via a manuscript, slide, poster, etc.) and the other is as a tool in analysis of data, that is, graphical data analysis. The criteria for what constitutes a good graph are sometimes at odds depending on which of these two purposes is being served—for example, a clear, simple, easily accessible presentation to make one specific point is often considered desirable for presentation of data, but complexity, information richness, and detail are usually paramount for graphical analysis. As a biostatistician, I’ve come to the point where I cannot do—and wouldn’t want to try to do – statistical analysis without performing graphical analysis in tandem with it, especially for exploratory research. Most graphs I make in my work are seen by no one but me. For graphical analysis, a good graph is information-rich and gives you at least a rough sense of the answers to many questions. A simple bivariate scatterplot, for example, gives one an immediate sense of the central tendency and variability of distributions of the variables plotted, whether the distributions are bell-shaped, skewed or show kurtosis, have floors or ceilings, whether there appears to be a linear or nonlinear relation between the variables, its nature and how strong it is, whether there are clusters of observations, univariate and bivariate outliers, influential observations, and so on. (Warning: some software may misleadingly hide, without notification, overlapping observations in a scatterplot — use jittering or symbols to convey multiplicity at a location, as needed). When symbols representing different categories, for example, groups, are plotted as the points in the scatterplot, the information content increases considerably as it does when fitted solid, dashed, dotted, etc. lines and curves are overlaid or the scatterplot is expanded to three dimensions or multiple panels are displayed. Color may be helpful, but exclusively relying on it to convey critical information to others is risky if the audience might not be able to see the colors for whatever reason (e.g., software, hardcopies, publications, photocopies might be colorless).
Graphs are also extremely useful for screening data for errors. Often errors, sometimes completely nonsensical ones, are hopelessly hidden in a rectangular dataset, but shout out when the data are graphed. Graphs are often necessary to see functions—for example, predicted values from some models are very difficult for most of us to visualize based on numbers alone. Such might be the case for regression coefficients for nonlinear and/or polynomial functions, especially when they are tangled up in complex interaction terms. In addition, graphs can provide comforting visual confirmation of a complex finding from a sophisticated analysis and/or let nonstatisticians “see” what the result of a complex analysis means.
Trying to do data analysis without graphs is like the old story of the blind men trying to describe an elephant after each one touches a different part of it (trunk, leg, tail, ear, body); each has a very limited and incomplete concept of the thing because they cannot see the whole object. A correlation coefficient (r), for example, conveys a very narrow, possibly misleading, slice of the wealth of information that can be seen in a scatterplot (including a rough idea of what the “r” value would be). Only rarely does a complex numerical index convey information that cannot be seen with the right graphs. A picture is worth a thousand words and a million numbers. A good figure for graphical analysis is like a detailed map; you can’t take it all in at once, but you can come back to it for reference to answer specific questions later or at least get a rough sense of what those answers are. A verbal translation of what a detailed map shows would require an encyclopedia of words and numbers. Also, one can focus on different aspects of a complex graph to answer different questions.
In addition to all these benefits of graphical analysis, I see a more fundamental reason why graphs are crucial to statistical research. I believe a quantity and quantitative relations in the abstract are better and more directly represented as visual images than as semantic symbols (“1”, “2”, “3”. . . .) which I think most of us have to mentally translate into some sort of cognitive images anyway. The graphical image IS the quantity; the number is a code for it, which must be processed, translated, and mentally visualized. Certainly any specific assertion one wishes to make suggested roughly by a graph will have to be confirmed and stated with precise numbers, for example, means, p-values, a partial correlation coefficient, and so on, but it is impossible to use a sea of numbers to explore what can be seen easily in an information-rich figure. And, of course, there is the problem of multiplicity in exploring data, graphically or otherwise. But that is a separate, age-old problem of exploratory analysis requiring cross-validation in an independent sample…..”
Joe Locascio,
Bio-Statistician
Neurology,
Mass. General Hospital & Harvard Med School
A fine addition to the growing list of experts who are pleading for the wiser choice of default options in graphic software. Bravo Naomi!
One might well ask why *any* graphic is necessary for just nine numbers across five categories (Figure 1)…
“Don’t waste it’s power on simple linear differences which are better summarized in a few numbers…wasting the tremendous communicative power of graphics to use them merely to decorate a few numbers.”
– Edward Tufte
There is another common thread here, which is to be thoughtful about your presentation, and explain what you are doing plainly. Clients will usually appreciate it, even if it is against their original instructions.
I agree that Fig 1 with its 9 numbers is a waste of graphical power. However, Fig 2 illustrates how a well-designed graphic of the same dataset can convey so much more interesting data. As statisticians, we should always be on the lookout for ways to improve upon the types and formats of graphics that clients, managers and even conference organizers request, as Naomi points out. Nice article!
I’m really amazed by how powerful graphics can be in conveying information to people without much statistical background, especially Figure 2. The diverging stacked bar chart looks really elegant and informative yet uncluttered. May I know is the R source codes for generating this graph already available to the public?
Faith,
The release date for R2.14.0 is scheduled for October 31st according to http://www.r-project.org. Rich Heiberger tells me that the next version of HH will be ready by then if not sooner.
Thanks Naomi for the information. Looking forward to the next release of the HH package. 🙂
The R code to produce the diverging stacked bar chart of Figure 2 is
now available on CRAN. See ?likert in the HH package, version 2.2-17
or later. Plots of counts, as well as the plots of percents as shown
Figure 2, are available. Options include adding a right axis (with
default value the total counts for the row), combining percent and
count plots, plots of higher dimensional arrays, vertical bars, and
different sorting options.
Welcome!
Amstat News is the monthly membership magazine of the American Statistical Association, bringing you news and notices of the ASA, its chapters, its sections, and its members. Other departments in the magazine include announcements and news of upcoming meetings, continuing education courses, and statistics awards.
ASA HOME
Departments
Archives
ADVERTISERS
PROFESSIONAL OPPORTUNITIES
FDA
US Census Bureau
Software
STATA
QUOTABLE
“ My ASA friendships and partnerships are some of my most treasured, especially because the ASA has enabled me to work across many institutional boundaries and
with colleagues from many types of organizations.”
— Mark Daniel Ward
Editorial Staff
Managing Editor
Megan Murphy
Graphic Designers / Production Coordinators
Olivia Brown
Meg Ruyle
Communications Strategist
Val Nirala
Advertising Manager
Christina Bonner
Contributing Staff Members
Kim Gilliam
Contact us
Amstat News
American Statistical Association
732 North Washington Street
Alexandria, VA 22314-1904
(703) 684-1221
www.amstat.org
Address Changes
Amstat News Advertising