Statistics Training: A Big Role in Big Data?
Two years in Silicon Valley causes professor to wonder about statistics’ role in Big Data
Lexin Li, Department of Statistics, North Carolina State University
“Big Data Is on the Rise, Bringing Big Questions,” proclaimed the title of a 2012 Wall Street Journal article. Big Data has become a buzzword in both the academic and business worlds. From a scientific perspective, Big Data refers to extracting useful information from large, diverse, distributed, and heterogeneous data sets to accelerate scientific discovery and innovation (NSF Big Data Initiative, 2012). From a business perspective, it means using integrated data storage, analytics, and applications to help drive efficiency, quality, and personalized products and services, and to create new levels of business value (EMC Business Overview).
Amid the present data deluge, the demand for data scientists is said to be huge. The 2011 McKinsey report, “Big Data: The Next Frontier for Innovation, Competition, and Productivity,” projected “a need for 1.5 million additional managers and analysts in the United States who can ask the right questions and consume the results of the analysis of Big Data effectively.” The same report claimed a significant constraint on realizing value from Big Data would be “a shortage of talent, particularly of people with deep expertise in statistics and machine learning, and the managers and analysts who know how to operate companies by using insights from Big Data.”
Another 2012 Wall Street Journal article, “Big Data’s Big Problem: Little Talent,” expressed similar concerns and suggested courses on Big Data don’t yet exist in universities: “[Though] bits of it do exist in various university departments and businesses, as an integrated discipline, it is only just starting to emerge.”
Statistics has long been in the center of data analysis. So what kind of role should our profession play in this wave of Big Data? What kind of training shall we provide in statistics departments to prepare our students to embrace the challenges of Big Data?
I joined the department of statistics at North Carolina State University in 2005 and I visited Yahoo Research Labs in 2011–2012 and the department of statistics at Stanford University in 2012–2013. During this period, I had opportunities to interact with many bright engineers and scientists, mostly from leading Internet technology companies such as Yahoo, Facebook, LinkedIn, Google, and EMC. These two years of experience in Silicon Valley prompted me to think about these questions frequently and, upon my return to NC State, led me to offer a special topics course on Big Data in the fall of 2013 to share my thoughts and experiences with our graduate students.
When preparing the course syllabus, I did some research to determine which topics to cover. I checked textbooks that are widely used for courses in computer science and statistics departments on data mining, which started to gain popularity about 15 years ago and shares many similarities with Big Data. I also studied a recent course, Mining Massive Data Sets, offered in the computer science department at Stanford. A summary of key topics covered in these books is given in Table 1. I find it interesting and informative when observing the evolution of topics in the two disciplines, then and now.
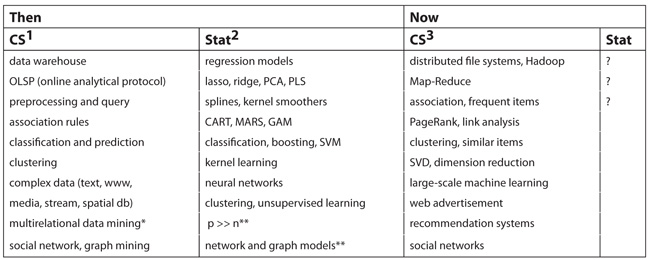
Table 1— Topics Covered in Data Mining and Big Data Courses, Then and Now
CS1: Han, J. and Kamber, M. 2000. Data Mining: Concepts and Techniques
Stat2: Hastie, T., R. Tibshirani, and J. Friedman. 2001. Elements of Statistical Learning
CS3: Rajaraman, A., J. Leskovec, and J.D. Ullman. 2014. Mining of Massive Datasets (manuscript).
Two sets of skills are commonly perceived as crucial for Big Data buy ativan no prescription mastercard analysis: the statistical skills to build and interpret appropriate models given the usually huge and complicated data and the engineering skills to carry out all necessary operations, including data retrieval, scalable optimization, and data visualization. For the first skill set, I chose to present a wide collection of data mining and machine learning topics, ranging from regularization, support vector machines, and boosting to more recent topics such as networks analysis, recommendation systems, and digitized advertising.
During the lectures, connections among different approaches (e.g., reproducing kernel learning and spline basis expansion) were emphasized. Model interpretation and inference also were highlighted. A parsimonious and interpretable model is favored often over a black box–type learning algorithm, even when it means one must sacrifice predictive accuracy to some extent. How to properly formulate a statistical model, develop intuitive insights and interpretation, and evaluate the uncertainty of the analysis were emphasized over purely algorithmic details.
For the second skill set, scalable and parallel algorithms were incorporated into the lectures. Erik Scott of the Renaissance Computing Institute of The University of North Carolina at Chapel Hill presented two guest lectures on the Hadoop distributed file system and Map-Reduce parallel computing framework. We designed a homework project in which students programmed and experimented on a small cluster of computers equipped with Hadoop. The majority of students were statistics majors, so this exercise offered them a unique opportunity to gain experience with modern computing and data processing techniques.
In addition to statistical and engineering skills, skills such as a deep understanding of the science or business so to ask the right questions and the ability to tell a concise story from the data and turn the analysis into a decision are equally important. But these skills are also the most difficult to learn. Toward that goal, I designed course projects in a format that differs substantially from what I used to assign in my other courses.
I selected a number of real data competitions (inactive) from www.kaggle.com and posed some high-level questions. Students were required to select a specific data set, formulate questions of interest, retrieve and process related data to support their analysis, carry out appropriate modeling and analysis of their choice, and concisely summarize their findings. These exercises both exposed students to problems and terminologies that are frequently encountered in the business world (e.g., personalized recommendation and the click-through rate) and helped students gain experience in handling real-world messy and big data sets. I also insisted on a concise summary of findings, with no more than three sentences, and an oral presentation strictly within five minutes. This new format contrasts with the old one, where I provided a clean data set, formulated the problem (specifying Xs and Ys), and concentrated on only the modeling step. In the Big Data course, the focus was shifted to the entire process of analysis, from problem formulation and data preparation to model building and summary.
The course was well received by the more than 40 registered and auditing students. Many stated in their course evaluations that they found the course particularly interesting and useful. To my knowledge, there are also a number of statistics faculty members offering or planning to offer a similar course at various universities, and efforts toward offering a data science master’s degree are under way at institutions including Berkeley, Columbia, and the University of Minnesota. With more such joint training efforts, our profession and graduates will hopefully play a big role in this Big Data revolution.








 (1 votes, average: 5.00 out of 5)
(1 votes, average: 5.00 out of 5)







Dear Prof,
Thanks for providing a much needed and a clearer focus on the skills required for this Big Data era. Could you also let me know if there are any course materials for this course which is accessible to self-learners like me ? If not, are there any good books / resources that you can kindly suggest ?