Hiring a Data Scientist
Note: This post applies to employers hiring data analysts, data scientists, statisticians, quantitative analysts, or any one of the dozen more titles used for descriptions of the job of “turning raw data into understanding, insight, and knowledge” (Wickham & Grolemund, 2016), the only differences being the skills and disciplines emphasized.
Mikhail Popov got his start with R and statistics at California State University, Fullerton, where he did undergraduate research in the application of statistics to neuroscience. He continued working with brain data as part of the master’s of statistical practice program at Carnegie Mellon University, followed by his employment at the Neuropsychology Research Program with the University of Pittsburgh Medical Center. These days, Popov is a data analyist for the Wikimedia Foundation, where his work focuses on supporting teams that improve the Wikipedia reading experience. He loves brewing coffee, cooking, baking, hiking, and sharing his knowledge with others.
We recently needed to backfill a data analyst position at the Wikimedia Foundation. If you’ve hired for this type of position in the past, you know it is no easy task—both for the candidate and the organization doing the hiring.
Based on our successful hiring process, we’d like to share what we learned and how we drew on existing resources to synthesize a better approach to interviewing and hiring a new member of our team.
Why Interviewing a Data Scientist Is Hard
It’s really difficult to structure an interview for data scientist positions. In technical interviews, candidates are often asked to recite or invent algorithms on a whiteboard. In data science interviews, specifically, candidates are often asked to solve probability puzzles that seem similar to homework sets in an advanced probability theory class. This shows they can memorize formulas and figure out the analytical solution to the birthday problem in five minutes, but it doesn’t necessarily indicate whether they can take raw, messy data and tidy it up, visualize it, glean meaningful insights from it, and communicate an interesting, informative story.
These puzzles, while challenging, often have nothing to do with actual data or the kinds of problems that would be encountered in an actual working environment. It can be both a frustrating experience for candidates and organizations alike—which is why we wanted to think about a better way to hire a data scientist for our team.
We also wanted our process to attract diverse candidates. As Stacy-Marie Ishmael, a John S. Knight Fellow at Stanford University and former managing editor for Mobile at BuzzFeed News, put it, “Job descriptions matter … and where they’re posted matter[s] even more.”
How to Write a Job Post That Attracts Good, Diverse Candidates
Defining ‘Data Scientist
The most obvious (but sometimes overlooked) issue in hiring a data scientist is figuring out what kind of skillset you’re actually looking for. The term “data scientist” is not standard; different people have different opinions about what the job entails depending on their background.
Jake VanderPlas, a senior data science fellow at the University of Washington’s eScience institute describes data science as “an interdisciplinary subject” that “comprises three distinct and overlapping areas: the skills of a statistician who knows how to model and summarize data sets (which are growing ever larger); the skills of a computer scientist who can design and use algorithms to efficiently store, process, and visualize this data; and the domain expertise—what we might think of as ‘classical’ training in a subject—necessary both to formulate the right questions and to put their answers in context.”
That’s more or less the description I personally subscribe to, and the description I’ll be using for the rest of this piece.
How to Ensure You’re Attracting a Diverse Group of Candidates
Now that you’ve defined data scientist, it’s necessary to move onto the next section of your job description: what a person will actually do!
The exact phrasing of job descriptions is important because research in this area has shown women feel less inclined to respond to “male-sounding” job ads and truly regard “required qualifications” as required qualifications. In a study of gendered wording in job posts by Danielle Gaucher et al. published in a 2011 Journal of Personality and Social Psychology article, they found “job advertisements for male-dominated areas employed greater masculine wording than advertisements within female-dominated areas” and “when job advertisements were constructed to include more masculine than feminine wording, participants perceived more men within these occupations and women found these jobs less appealing.”
We had a job description (JD) that was previously used for hiring me, but it wasn’t perfect. It included lines like “experience contributing to open source projects,” which could result in preference for people who enter and stay in the open source movement because they don’t experience the same levels of harassment others experience or a preference for people who have the time to contribute to open source projects (which may skew toward a certain type of person.)
We consulted Geek Feminism wiki’s how-to on recruiting and retaining women in tech workplaces and the solutions to reducing male bias in hiring when rewriting the job description so to not alienate any potential candidates. From that document, we decided to remove an explicit requirement for years of experience and called out specific skills women are socialized to be comfortable with associating with themselves, adding time management to required skills and placing greater emphasis on collaboration.
Once we finished this draft, we asked for feedback from several colleagues who we knew to be proponents of diversity and intersectionality.
A super important component of this: We did not want to place the burden of diversifying our workforce on the women or people of color in our workplace. Ashe Dryden, an inclusivity activist and expert on diversity in tech spaces, wrote, “Often the burden of fostering diversity and inclusion falls to marginalized people” and “all of this is often done without compensation. People internal to the organization are tasked with these things and expected to do them in addition to the work they’re already performing.”
We strongly believe everyone is responsible for this, and much has been written about how the work of “[diversifying a workplace] becomes a second shift, something [members of an under-represented group] have to do on top of their regular job.” To remedy this, we specified colleagues to give feedback during their office hours, when/if they had time for it (so it wouldn’t negatively affect their work) and only if they actually wanted to help out.
From the feedback, we rephrased some points and included encouragement for a diverse range of applicants (“Wikimedia Foundation is an equal opportunity employer, and we encourage people with a diverse range of backgrounds to apply. We also welcome remote and international applicants across all time zones.”). We then felt confident publishing the job description, which our recruiters advertised on services like LinkedIn. In addition, we wanted to advertise the position where DataSci women would congregate, so I reached out to a friend at R-Ladies (a network of women using R) who was happy to let the mailing list know about this job opening.
In short, be proactive, go where people already congregate, and ensure your language in a job post is as inclusive as possible and you will likely attract a wider pool of potential candidates.
Sample Job Description
You might be asking yourself, “So what did this job description actually look like?” Here it is, with important bits bolded and two italicized notes interjected:
- Work closely with product managers to build out and maintain detailed ongoing analysis of the department’s products, their usage patterns, and performance.
- Write database queries and code to analyze Wikipedia usage volume, user behavior, and performance data to identify opportunities and areas for improvement.
- Collaborate with the other analysts in the department to maintain our department’s dashboards, ensuring they are up to date, accurate, fair, and focused representations of the efficacy of the products.
- Support product managers through rapidly surfacing positive and adverse data trends, and complete ad hoc analysis support as needed.
- Communicate clearly and responsively your findings to a range of departmental, organizational, volunteer, and public stakeholders—to inform and educate them.
The Wikimedia Foundation is looking for a pragmatic, detail-oriented data analyst to help drive informed product decisions that enable our communities to achieve our vision: a world in which every single human being can freely share in the sum of all knowledge.
Data analysts at the Wikimedia Foundation are key members of the product team who are the experts within the organization on measuring what is going on and using data to inform the decision-making process. Their analyses and insights provide a data-driven approach for product owners and managers to envision, scope, and refine features of products and services that hundreds of millions of people use around the world.
You will join the Discovery Department, where we build the anonymous path of discovery to a trusted and relevant source of knowledge. Wikimedia Foundation is an equal opportunity employer, and we encourage people with a diverse range of backgrounds to apply. We also welcome remote and international applicants across all time zones.
As a Data Analyst, you will:
Notice the emphasis on collaboration and communication—the social aspect, rather than technical aspect, of the job.
Requirements:
- Bachelor’s degree in statistics, mathematics, computer science, or other scientific fields (or equivalent experience).
- Experience in an analytical role extracting and surfacing value from quantitative data.
- Strong eye for detail and a passion for quickly delivering results for rapid action.
- Excellent written, verbal, scientific communication and time-management skills.
- Comfortable working in a highly collaborative, consensus-oriented environment.
- Proficiency with SQL and R or Python.
Pluses:
- Familiarity with Bayesian inference, MCMC, and/or machine learning.
- Experience editing Wikipedia or with online volunteers.
- Familiarity with MediaWiki or other participatory production environment.
- Experience with version control and peer code review systems.
- Understanding of free culture / free software / open source principles.
- Experience with JavaScript.
Notice how we differentiate between requirements and pluses. Other than SQL and R/Python, we don’t place a lot of emphasis on technologies and specific advanced topics in statistics. We hire knowing the candidate is able to learn Hive and Hadoop and that they can learn about multilevel models and Bayesian structural time series models if a project requires it.
Benefits & Perks*:
- Fully paid medical, dental, and vision coverage for employees and their eligible families (yes, fully paid premiums!)
- The Wellness Program provides reimbursement for mind, body, and soul activities such as fitness memberships, massages, cooking classes, and much more
- The 401(k) retirement plan offers matched contributions at 4% of annual salary
- Flexible and generous time off—vacation, sick, and volunteer days
- Pre-tax savings plans for health care, child care, elder care, public transportation, and parking expenses
- For those emergency moments—long- and short-term disability, life insurance (2x salary), and an employee assistance program
- Telecommuting and flexible work schedules available
- Appropriate fuel for thinking and coding (aka, a pantry full of treats) and monthly massages to help staff relax
- Great colleagues—international staff speaking dozens of languages from around the world, fantastic intellectual discourse, mission-driven and intensely passionate people
* for benefits-eligible staff; benefits may vary by location
Take-Home Task
Many engineering and data science jobs require applicants to complete problems on a whiteboard. We decided not to do this. As Tanya Cashorali, the founder of TCB Analytics, put it, “[Whiteboard testing] adds unnecessary stress to an environment that’s inherently high stress and not particularly relevant to real-world situations.” Instead, we prefer to give candidates a take-home task. This approach gives candidates the opportunity to perform the necessary background research, get acquainted with the data, thoroughly explore the data, and use the tools they are most familiar with to answer questions.
After our candidates passed an initial screening, they were given 48 hours to complete a data analysis task, inspired by an S&D data analyst task I had completed during my interview process. The tasks were designed so the candidate would have to do the following:
- Develop an understanding and intuition for the provided data set through exploratory data analysis
- Demonstrate critical thinking and creativity
- Deal with real-world data and answer actual, potentially open-ended questions
- Display knowledge of data visualization fundamentals
- Write legible, commented code
- Create a reproducible report (e.g., include all code, list all dependencies) with a summary of findings
We recommend designing a task that uses your own data and a question you’ve answered previously to give candidates an example of their day-to-day work in the future. If your team or organization has worked on a small-scale, data-driven project to answer a particular business question, a good starting point would be to convert that into the take-home task.
Interview Questions
Now that you have your candidates, you have to interview them. This, too, can be tricky, but we wanted to judge each candidate on their merits, so we created a matrix ahead of time that could measure their answers.
We wanted to emphasize how our prospective applicants thought about privacy and ethics. From how we handle requests for user data to our public policy on privacy, our guidelines for ethically researching Wikipedia, and our conditions for research efforts, it is clear that privacy and ethical considerations are important to the Wikimedia Foundation. We wanted to ensure final candidates could both handle the data and privacy concerns that come with this job.
When we thought about the sorts of questions we’ve been asked in previous interviews and the kinds of topics that were important for us, we devised the following goals:
- Assess candidate’s critical thinking and research ethics
- Require candidate to interpret, not calculate/generate, results
- Learn about candidate’s approach to analysis
- Gauge candidate’s awareness/knowledge of important concepts in statistics and machine learning
To that end, I asked the candidates some or all of the following questions:
- What do you think are the most important qualities for a data scientist to have?
- Data Analysis:
-
—What are your first steps when working with a data set? (“Exploratory data analysis” is too vague! Inquire about tools they prefer and approaches that have worked for them in the past.)
—Describe a data analysis you had the most fun doing. What was the part you personally found the most exciting?
—Describe a data analysis you found the most frustrating. What were the issues you ran into and how did you deal with them?
I used the following questions to assess the candidate’s ability to identify ethics violation in a clear case of scientific misconduct because I wanted to work with someone who understood what was wrong with the case, knew why it was wrong, but also could devise a creative solution that would respect privacy. First, I asked if they’d heard about the OKCupid fiasco. If they hadn’t, I briefly caught them up on the situation, described how answers on OKCupid work (if they didn’t know), and specifically mentioned that the usernames were left in the data set.
- Please discuss the ethical problems with compiling this data set in the first place and then publicly releasing it.
- You’re an independent, unaffiliated researcher. Maybe you’re a researcher here at the foundation, but you worked on this project in your personal capacity outside of work. Describe the steps you might take to make the individuals in the data set less easily re-identifiable and the kinds of steps you might take before releasing the data set.
- Concepts in Statistics:
-
—Statistical power, p-value, and effect size make up an important trio of concepts in classical statistics that relies on null hypothesis significance testing. As Andrew Gelman, a professor of statistics at Columbia University, writes, “Naïve (or calculating) researchers really do make strong claims based on p-values, claims that can fall apart under theoretical and empirical scrutiny”. I presented the outcome of a large sample size (e.g., 10K subjects) A/B test that yielded tiny (e.g., odds ratio of 1.0008) but statistically significant (e.g., p < 0.001) results, and then I asked if we should deploy the change to production. Why or why not?
—Bootstrapping is a popular and computationally intensive tool for nontraditional estimation and prediction problems that can’t be solved using classical statistics. While there may be alternative nonparametric solutions to the posed problem, the bootstrap is the simplest and most obvious for the candidate to describe, and we consider it an essential tool in a data scientist’s kit. I asked the candidate how we might approach an A/B test in which we developed a new metric of success and a similarity measure that we can’t use any of the traditional null hypothesis significance tests for.
—Not satisfying the assumptions in statistical models can lead the scientist to wrong conclusions by making invalid inferences. It was important for us that the candidate was aware of the assumptions in the most common statistical model and understood if/how the hypothetical example violated those assumptions. Furthermore, we wanted to see whether the candidate could offer a more valid alternative from—for example—time series analysis, to account for temporal correlation. “One of the things we’re interested in doing is detecting trends in the usage of our APIs—interfaces we expose to the public so they can search Wikipedia. Say I’ve got this time series of daily API calls in the millions and I fit a simple linear regression model to it and I get a positive slope estimate of 3,000 from which I infer that use of our services is increasing by 3,000 API calls every day. Was this a correct solution to the problem? What did I do wrong? What would you do to answer the same question?”
- Concepts in Machine Learning:
-
—Model Tuning: Many statistical and machine learning models rely on parameters (and hyperparameters) that must be specified by the user. Sometimes, software packages include default values, and sometimes those values are calculated from the data using recommended formulas—for example, for a data set with p features in the example below, m would be √p. A data scientist should not always use the default values and needs to know how parameter tuning (usually via cross-validation) is used to find a custom, optimal value that results in the smallest errors but also avoids overfitting. First, I asked if they knew how a random forest works in general and how its trees are grown. If not, it was not a big deal because I’m not interested in their knowledge of a particular algorithm. I reminded them that, at every split, the algorithm picks a random subset of m features to decide which predictor to split on, and then I asked what m they’d use.
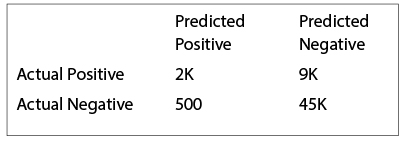
—Model Evaluation: It’s not enough to be able to make a predictive model of the data. Whether forecasting or classifying, the analyst needs to be able to assess whether their model is good, how good it is, and what its weaknesses are. In the example below, the classification model might look good overall (because it’s really good at predicting negatives since most of the observations are negatives), but it’s actually terrible at predicting positives! The model learned to maximize its overall accuracy by classifying observations “negative” most of the time. “Let’s say you’ve trained a binary outcome classifier and got the following confusion matrix. This comes out to misclassification rate of 17%, sensitivity of 99%, specificity of 18%, prevalence of 80%, positive predictive value of 83%. Pretend I’m a not-so-technical executive and I don’t know what any of these numbers mean. Is your model good at predicting? What are its pitfalls, if any?”
It Worked!
Based on this process, we successfully hired Chelsy Xie—who writes awesome reports, makes fantastic additions to Discovery’s dashboards (like sparklines and full geographic breakdowns), and (most importantly) is super inquisitive and welcomes a challenge (core traits of a great data scientist).
This process was easier, in part, because Chelsy was not the first data scientist hired by the Wikimedia Foundation; our process was informed by having gone through a previous hiring cycle, and we were able to improve during this iteration.
It’s harder for employers who are hiring a data scientist for the first time because they may not have someone on their team who can put together a data scientist–oriented interview process and design an informative analysis task. Feel free to use this guide as a way to navigate the process for the first time, or for improving your existing process.
This isn’t the only way to interview a candidate for a data scientist position, nor is it the best way. Much of our thinking on how to approach this task was shaped by our own frustrations as applicants, as well as our experience of what data scientists actually do in the workforce. These insights likely also apply to hiring pipelines in other technical disciplines.
We are also interested in continually improving and iterating this process. If you have additional tips or would like to share best practices from your own data scientist hiring practices, please share them.
References and further reading can be found on the original blog post.
Editor’s Note: This article was reprinted from the Wikimedia blog and is licensed under CC BY 3.0.








 (No Ratings Yet)
(No Ratings Yet)






